Category
techtalksWie behalten wir den Überblick über unsere Systeme, insbesondere bei verteilten Anwendungen? Welche Metriken, Logs und Traces helfen uns wirklich weiter?
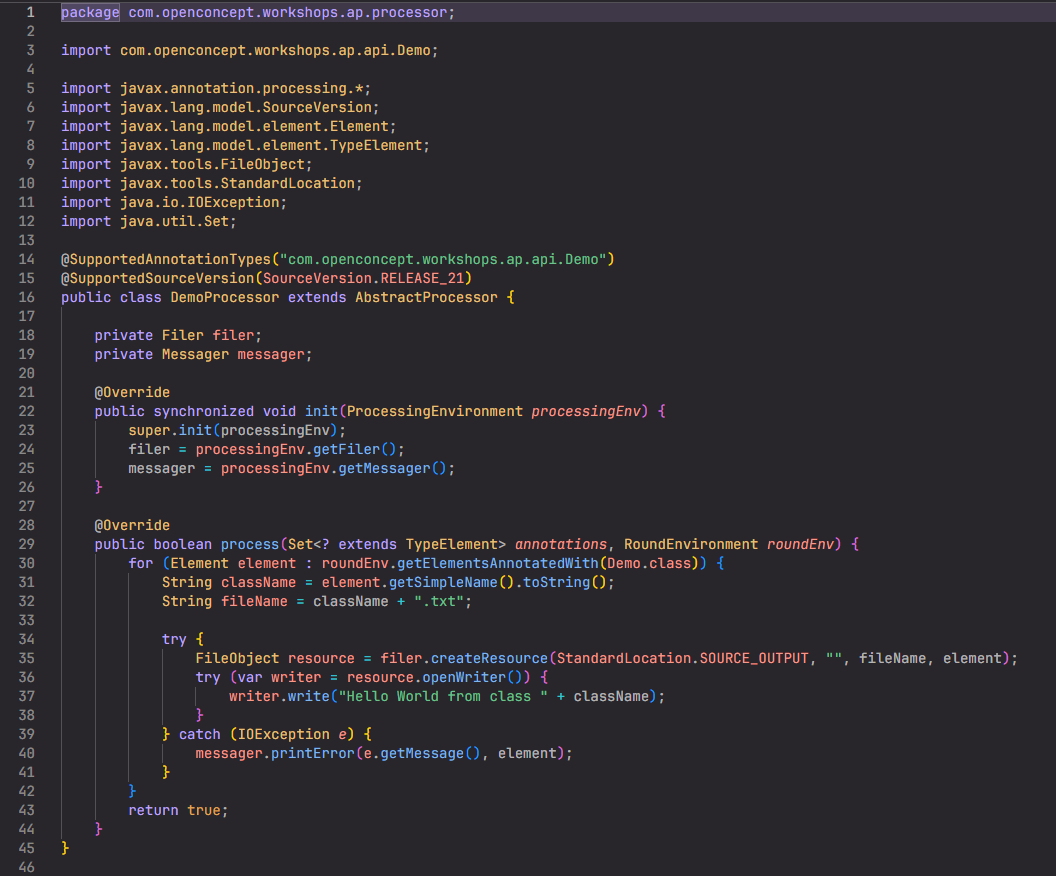
Observability geht über klassisches Monitoring hinaus. Mit OpenTelemetry können wir Daten sammeln und analysieren, um Einblicke in das Verhalten unserer Systeme zu gewinnen. Aber wie nutzen wir diese Tools – etwa Prometheus und Grafana – am effektivsten?
Welche Herausforderungen gibt es bei der Integration von Observability in bestehende Systeme, und welche Best Practices haben sich in der Praxis bewährt? Wie können wir Fehler frühzeitig erkennen, bevor sie zu echten Problemen werden?